

Master Event Sourcing JavaScript: Build Scalable Apps
A SaaS team usually discovers its data model is broken at the worst possible moment. Billing numbers don’t match. A customer claims a downgrade was applied twice. Support sees the current subscription state, but nobody can explain how it got there. Engineering finds a bad deployment from last week, yet there’s no clean way to reconstruct what the record looked like before the bug.
That’s the data problem most growing systems create for themselves. Traditional CRUD storage keeps the latest version of a row and throws away the story behind it. That works until your product has approvals, retries, billing adjustments, CRM state changes, and automations firing from several services at once.
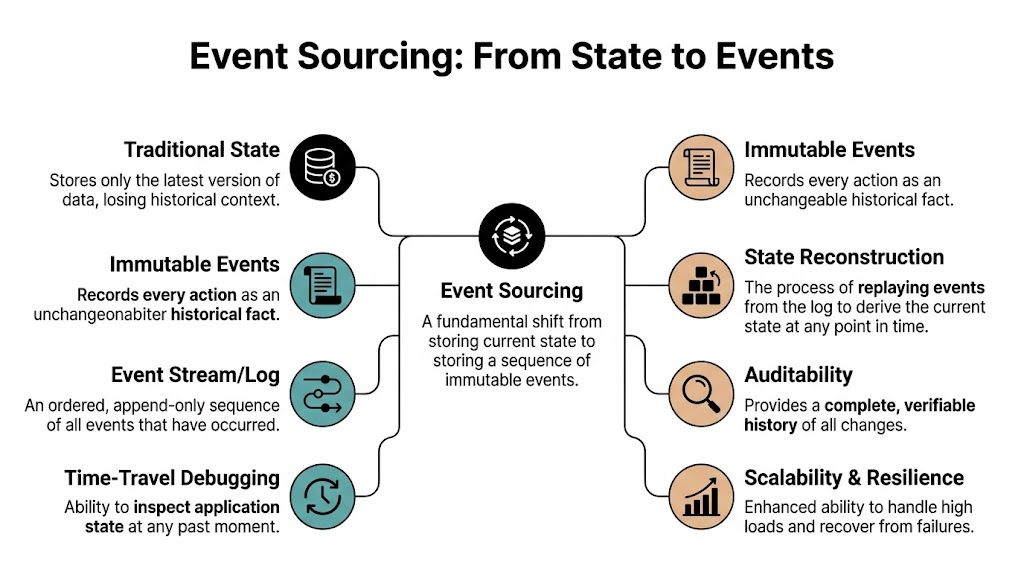
Event sourcing javascript solves that problem by changing what you treat as the source of truth. Instead of storing only current state, you store every state change as an immutable fact. Current state becomes a derived view, not the primary record. For SaaS companies, that shift matters far beyond engineering elegance. It gives you auditability, better debugging, safer workflow automation, and cleaner analytics.
Introduction The Data Problem You Don't Know You Have
Data models often break at the worst possible moment.
A customer disputes an invoice. Support can see the subscription is canceled, finance can see a credit was issued, and engineering can see a webhook retried three times. Nobody can answer the simple question that matters: what happened, in what order, and which system made each change?
A plain subscriptions table works for a while. Then the product picks up the behavior that makes SaaS valuable and hard to reason about. Mid-cycle upgrades. Manual credits. Retry jobs. Sales-assisted changes. Approval flows. Usage adjustments. By that point, a single current-state row is carrying far more meaning than it was designed to hold.
CRUD storage gives you the latest value. It does not give you a reliable history of how that value was produced. When a deployment writes bad state, you can see the record is wrong. You usually cannot reconstruct which change was legitimate, which one was duplicated, and what the customer should have been charged.
That stops being a schema problem and becomes an operating problem.
Practical rule: If support, finance, and engineering need different explanations for the same customer record, the system already depends on history. The database just is not storing that history in a trustworthy way.
Event sourcing addresses that by storing each business change as an immutable fact. For a subscription, that might mean purchased, upgraded, prorated, coupon applied, paused, resumed, and canceled. The current state still matters, but it is a result you derive from the sequence, not the only record you keep.
For SaaS companies, the payoff is practical:
- Audit logs you can trust: You can show who changed what, when they changed it, and what happened before and after.
- Workflow debugging that does not turn into guesswork: Failed automations, duplicate retries, and out-of-order updates become visible instead of buried inside overwritten rows.
- Safer downstream systems: Billing, notifications, CRM syncs, and analytics can all work from the same historical record.
- Better answers for customers and finance: Disputes get resolved faster when the system can explain the sequence instead of only exposing the final state.
There is a real cost. Event sourcing adds modeling work, operational overhead, and discipline around event design. Teams with weak domain boundaries can make the system harder to understand instead of easier. But for a SaaS product that depends on auditability, complex workflows, and historical reporting, that cost often buys something CRUD systems struggle to provide: a system of record that explains itself.
Understanding The Core Idea of Event Sourcing
Event sourcing shifts the data model from storing current state to storing a record of business changes over time. Instead of overwriting a subscription row every time a customer upgrades, pauses, or cancels, the system appends events that describe each step.
Events are facts, not updates
An event records something that happened in the domain. In a SaaS product, that might be PlanPurchased, Upgraded, CouponApplied, ProRated, or Canceled. Those names matter because they preserve business meaning instead of flattening everything into generic field changes.
A CRUD model asks for the latest value. An event-sourced model records the sequence that produced it. That difference matters when finance asks why an invoice changed, support needs to explain a failed renewal, or product wants to analyze how accounts move between plans.
Events are immutable. If the business changes something later, the system appends a new fact instead of editing the old one. That is what makes the history reliable enough for audits, billing reviews, and workflow debugging.
The event store becomes your source of truth
In event sourcing, the event store is the append-only log of those facts. Current state still exists, but it is derived from the event stream rather than treated as the only record that matters.
In JavaScript systems, an aggregate such as a user account, invoice, or CRM lead can be rebuilt by loading its stream and applying each event in order. That replay model gives teams something standard row updates rarely provide. The ability to reconstruct past state, trace exactly how a record changed, and rebuild downstream views after fixing a bug.
If you work in distributed systems, it also helps to understand how this fits within a broader event-driven architecture. Event sourcing and event-driven architecture solve different problems. Event sourcing gives you a durable business history. Event-driven architecture defines how services publish and react to events across the system.
Aggregates define the boundary
The next key idea is the aggregate. An aggregate is the consistency boundary that owns a stream of events and enforces business rules. That boundary matters because it prevents random parts of the codebase from appending conflicting events to the same entity.
For example, a Subscription aggregate might enforce rules like:
- No duplicate purchase: You cannot purchase an already active plan.
- Valid downgrade path: A downgrade cannot happen if cancellation is already effective.
- Ordered transitions: Proration only happens after a qualifying billing change.
This is the part many JavaScript examples skip. Event sourcing is not just storing logs in a table. The aggregate decides whether a command is valid, then emits one or more events that become the permanent record.
Store domain facts, not UI actions.
LeadQualifiedages well.ButtonClickedusually doesn’t.
Rehydration is how state comes back
To use an aggregate, you rehydrate it. That means loading its past events and applying them in sequence until current state emerges.
A simplified model looks like this:
- Start with an empty state.
- Read the aggregate’s events in order.
- Apply each event to evolve state.
- Run a command against the rebuilt aggregate.
- If valid, append new event or events.
This approach feels unusual at first in JavaScript because developers are used to mutating records directly. Here, the flow is different. Rebuild state, evaluate the command, append facts.
There is a cost. Long event streams increase replay work, and bad event design creates pain that a simple CRUD app would avoid. In return, SaaS teams get a system that can explain itself, which is hard to overstate once audits, billing disputes, retries, and cross-service workflows become part of daily operations.
Essential Architecture Patterns for JavaScript
A SaaS team usually feels the strain before they name the pattern problem. Support asks for a full billing history on one enterprise account. Product wants a dashboard that answers, "Which trials converted after a pricing change?" Engineering sees command latency rise on a few hot accounts with years of history. Event sourcing can handle all of that, but only if the architecture around it is deliberate.

CQRS separates write models from read models
CQRS splits command handling from querying. The write side protects business rules and appends events. The read side reshapes those events into data structures that fit the product.
That separation matters in real SaaS systems. The event stream for a subscription might be perfect for correctness and auditability, but poor for rendering an account page, driving a finance report, or powering a success team's renewal queue. Those jobs need different data shapes, update frequencies, and indexes.
In JavaScript and TypeScript codebases, the write model usually centers on an apply or evolve function that folds events into current state. The TypeScript and Node.js event sourcing guide is a useful reference for that style of implementation. The main operational point is simpler than any benchmark. Replaying events is often cheap enough for many aggregates, while query workloads still benefit from dedicated read models.
A practical read stack usually includes:
- Operational projections: account pages, invoice lists, onboarding status, approval queues
- Audit projections: ordered histories for support, compliance, and billing disputes
- Analytics projections: reporting tables for MRR movement, funnel analysis, and cohort work
Teams that get this right stop forcing one database shape to satisfy every use case. If you are comparing storage options for those views, this guide on database patterns in Node.js complements the design work well.
Projections turn event history into product features
A projection consumes events and updates a denormalized view. This is how event sourcing becomes usable for the business, not just correct for engineers.
For a subscription system, one stream can feed several projections at once:
| Read model | Purpose |
|---|---|
| Current subscription view | Fast app rendering |
| Billing audit timeline | Support and finance investigation |
| Revenue movement projection | Reporting and forecasting |
| Customer lifecycle summary | CRM and success workflows |
This pattern pays off when requirements change. Add a new customer success workflow, and you can build a projection for expansion risk without rewriting the billing aggregate. Find a bug in a reporting view, and you can fix the projector and rebuild from history. In a CRUD system, bad writes often leave you repairing rows by hand and guessing what happened.
The event log holds the source of truth. Projections exist to answer specific questions quickly.
Snapshots reduce replay work on hot aggregates
Replay cost grows with stream length. That is manageable for many aggregates, then painful for a small set that change constantly, such as subscriptions, carts, approval workflows, or tenant accounts with lots of settings changes.
A snapshot stores aggregate state at a known version. Command handling loads that saved state first, then replays only the events written after it. The underlying idea is straightforward. Trade some storage and versioning complexity for lower rehydration cost on streams that justify it.
Snapshots are unnecessary for most aggregates initially.
A practical rule set looks like this:
- Start without snapshots: keep the model simple until stream length becomes a measured problem
- Measure command latency: add snapshots because data justifies it, not because the pattern is available
- Use them for high-churn aggregates: focus on entities that take repeated writes over long periods
- Treat snapshots as disposable optimizations: the event stream remains the authority
- Version snapshot schemas carefully: old snapshots must not corrupt rehydration after model changes
That last point matters in production. A broken snapshot strategy creates subtle bugs that are harder to trace than slow replay. The gain is real, but so is the maintenance cost.
Concurrency and ordering need explicit control
Once multiple workers, pods, or services can write to the same aggregate, append order matters. Two individually valid commands can still create an invalid history if they land out of sequence.
Event stores solve this with optimistic concurrency. Load stream version N, run the command, then append only if the stream is still at N. If another writer already appended version N+1, reject the write or retry after rehydrating.
This is one of the places where event sourcing pays off for SaaS companies with real workflow complexity. You get an audit trail and deterministic business history, but only if writes are protected by version checks. Skip that, and "event sourcing javascript" turns into a race condition with better naming.
Building a System with Event Sourcing in Node.js
A SaaS team usually feels the need for event sourcing after a painful incident. Support asks who changed a customer’s plan. Finance asks why an invoice was voided. Product wants a funnel report based on status transitions that were never stored. A CRUD model can answer parts of that story. An event stream can answer the whole thing.
A shopping cart is still a good example because the rules are familiar, but the same implementation pattern works for subscriptions, invoices, CRM pipelines, approval flows, and onboarding checklists. The value is not the cart. The value is a system that records every business decision in order.
The design has four parts:
- Events that represent business facts
- An aggregate that validates commands and applies events
- An event store that appends and loads streams
- A service layer that rehydrates, executes, and persists
The Node.js ecosystem is mature enough that you do not need to invent the whole application shell yourself. If you are still shaping the surrounding service boundaries, routing, and deployment model, this guide to building Node.js apps is a useful companion.
Define events with business meaning
Start with domain events, not tables or endpoints. In TypeScript, keep them explicit:
type CartEvent =
| { type: 'ShoppingCartOpened'; data: { cartId: string; customerId: string } }
| { type: 'ProductAdded'; data: { productId: string; quantity: number } }
| { type: 'ProductRemoved'; data: { productId: string } }
| { type: 'ShoppingCartConfirmed'; data: { confirmedAt: string } }
| { type: 'ShoppingCartCanceled'; data: { canceledAt: string; reason: string } };
These names carry real operational value. ProductAdded gives support, analytics, and compliance teams a durable fact they can trust later. UpdateCartRow does not. It describes a storage action, not a business event.
That distinction matters more as the company grows. Once sales ops, billing, and customer success all depend on the same history, vague event names become expensive.
Build the aggregate around commands and apply logic
The aggregate holds current state in memory while it processes a command. It decides whether the action is allowed, emits new events, then applies them locally so state stays consistent.
type CartState = {
id?: string;
customerId?: string;
status: 'empty' | 'open' | 'confirmed' | 'canceled';
items: Record<string, number>;
};
const initialState: CartState = {
status: 'empty',
items: {}
};
function evolve(state: CartState, event: CartEvent): CartState {
switch (event.type) {
case 'ShoppingCartOpened':
return {
...state,
id: event.data.cartId,
customerId: event.data.customerId,
status: 'open'
};
case 'ProductAdded':
return {
...state,
items: {
...state.items,
[event.data.productId]:
(state.items[event.data.productId] || 0) + event.data.quantity
}
};
case 'ProductRemoved': {
const items = { ...state.items };
delete items[event.data.productId];
return { ...state, items };
}
case 'ShoppingCartConfirmed':
return { ...state, status: 'confirmed' };
case 'ShoppingCartCanceled':
return { ...state, status: 'canceled' };
}
}
Now wrap that in command methods:
class ShoppingCart {
private state: CartState;
private pending: CartEvent[] = [];
constructor(state: CartState = initialState) {
this.state = state;
}
static fromHistory(events: CartEvent[]) {
const state = events.reduce(evolve, initialState);
return new ShoppingCart(state);
}
open(cartId: string, customerId: string) {
if (this.state.status !== 'empty') throw new Error('Cart already exists');
this.record({ type: 'ShoppingCartOpened', data: { cartId, customerId } });
}
addProduct(productId: string, quantity: number) {
if (this.state.status !== 'open') throw new Error('Cart is not open');
if (quantity <= 0) throw new Error('Quantity must be positive');
this.record({ type: 'ProductAdded', data: { productId, quantity } });
}
confirm(confirmedAt: string) {
if (this.state.status !== 'open') throw new Error('Only open carts can be confirmed');
if (Object.keys(this.state.items).length === 0) throw new Error('Cannot confirm empty cart');
this.record({ type: 'ShoppingCartConfirmed', data: { confirmedAt } });
}
private record(event: CartEvent) {
this.state = evolve(this.state, event);
this.pending.push(event);
}
flushPending() {
const events = [...this.pending];
this.pending = [];
return events;
}
getState() {
return this.state;
}
}
This split between evolve and command methods is worth keeping strict. evolve answers, "what does this event do to state?" The command methods answer, "is this action allowed right now?" Mixing those concerns usually leads to hidden rules, duplicate checks, and brittle tests.
Use a simple event store first
Start with a store interface that proves the model and its failure cases. You need ordered append, stream loading, and version checks. That is enough to validate the business flow before you commit to infrastructure choices.
type StoredEvent = CartEvent & {
streamId: string;
version: number;
};
class InMemoryEventStore {
private streams = new Map<string, StoredEvent[]>();
async load(streamId: string): Promise<StoredEvent[]> {
return this.streams.get(streamId) || [];
}
async append(streamId: string, events: CartEvent[], expectedVersion: number) {
const stream = this.streams.get(streamId) || [];
if (stream.length !== expectedVersion) {
throw new Error('Concurrency conflict');
}
const stored = events.map((event, index) => ({
...event,
streamId,
version: expectedVersion + index + 1
}));
this.streams.set(streamId, [...stream, ...stored]);
}
}
That expectedVersion check is what protects the business history from overlapping writes. In a SaaS product, that matters when billing jobs, admin actions, API calls, and background automations can all touch the same aggregate.
Wire it together in an application service
The application service runs the full command flow. It loads history, rebuilds the aggregate, executes the command, and persists the new events.
class CartService {
constructor(private store: InMemoryEventStore) {}
async addProduct(cartId: string, productId: string, quantity: number) {
const history = await this.store.load(cartId);
const cart = ShoppingCart.fromHistory(history);
cart.addProduct(productId, quantity);
const pending = cart.flushPending();
await this.store.append(cartId, pending, history.length);
return cart.getState();
}
}
That is the entire write path. Load history. Rehydrate. Decide. Append.
In production, teams usually add metadata alongside each event: who triggered it, request ID, tenant ID, correlation ID, and timestamp. Those fields are not decoration. They turn the event stream into an audit log your support, finance, and compliance teams can use.
Replay performance and snapshot frequency depend on aggregate size, event payload shape, and storage choice. Keep the first version simple. Measure rehydration time under real traffic, then add snapshots only where long-lived aggregates create noticeable latency.
What this looks like in SaaS
Replace ShoppingCartConfirmed with LeadQualified, ProposalSent, ContractApproved, SubscriptionUpgraded, or InvoiceVoided, and the pattern becomes much more interesting than a demo app.
A product team gets a reliable history of workflow transitions. Support gets a defensible answer to "what changed?" Finance gets traceable billing state changes. Data teams get event streams that are far easier to project into analytics pipelines than reverse-engineering meaning from row updates. That business payoff is why event sourcing keeps showing up in serious SaaS systems, even with the extra complexity.
The trade-off is real. Teams have to model behavior carefully, version events deliberately, and accept that read models are a separate concern. But if the product needs auditability, complex workflows, and trustworthy historical analysis, this architecture earns its keep.
Production-Ready Event Sourcing Strategies
A demo survives happy paths. A production SaaS system has to survive retries, partial deploys, schema changes, and support tickets that depend on reconstructing exactly what happened six months ago.

Test behavior, not storage trivia
Testing gets simpler when aggregates stay pure. Feed in prior events, issue a command, and assert on the emitted events or the rejection. That gives fast feedback on business rules without dragging the event store, queue, or projector infrastructure into every test.
A strong aggregate test usually follows this shape:
- Given history: a stream of prior events
- When command: a business action is attempted
- Then result: expected new events or expected rejection
Example cases for a SaaS subscription aggregate:
- Upgrade after cancellation: should reject
- Apply coupon before purchase: should reject
- Downgrade active annual plan: should emit a downgrade event and any required billing adjustment event
- Replay legacy stream: should still build current state correctly
Integration tests have a different job. Verify append ordering, projection updates, idempotency, and restart recovery. If a projector processes the same event twice after a crash, the read model should still end up correct. If a rebuild takes three hours in staging, that is a production concern, not a test footnote.
Schema evolution breaks systems more often than throughput does
Schema evolution causes more real pain than raw event volume for many SaaS teams. Product definitions change. Billing rules change. Approval workflows gain exceptions. The event log has to carry old decisions forward without corrupting current behavior.
The earlier OneUptime article linked from this article discusses schema evolution in Node.js event sourcing, but the specific failure percentage is not cited directly on that page, so it is better to avoid the number and keep the practical point. Upcasting, parallel event types, and temporary dual-write migrations are common ways to keep a system usable while the domain keeps changing.
Here’s a practical upcasting example.
Suppose your old event looked like this:
{ type: 'LeadScored', data: { score: 82 } }
Later, product needs explainability and model source:
{ type: 'LeadScored', data: { score: 82, model: 'v2', reasons: ['intent', 'engagement'] } }
You have three options:
| Strategy | When it works | Trade-off |
|---|---|---|
| Upcast on read | Small to medium changes | Adds translation logic to rehydration |
| Parallel event types | Big semantic changes | More projector complexity |
| Dual-write during migration | Gradual cutovers | Temporary operational overhead |
Use upcasting when old and new events still mean the same thing. Introduce a new event type when the business meaning changed. Mixing incompatible meanings under one event name saves time for a sprint and creates replay bugs for years.
Versioning pain usually appears after the product starts making real money. A workflow that drives expansion revenue cannot stop replaying correctly because the payload from last year no longer matches this quarter’s rules.
Scale by isolating hot paths
Event-sourced systems typically do not require heroic scaling early. They require clear boundaries and operational discipline.
Use these checkpoints:
- Snapshot hot aggregates: focus on entities with long histories and frequent writes.
- Partition streams by aggregate identity: avoid creating a global write bottleneck when the domain can stay isolated.
- Keep projectors idempotent: retries and replays should not duplicate balances, invoices, or workflow states.
- Separate operational reads from analytics reads: product screens, support tools, and BI workloads should not compete for the same projection path.
For teams pushing domain events into a broader async platform, Kafka-based data pipeline patterns become useful once projections, downstream consumers, and warehouse syncs need higher throughput and cleaner isolation.
After you’ve stabilized the architecture, it helps to see another engineer walk through practical trade-offs in system evolution and replay concerns:
What fails in production
A few mistakes show up repeatedly in SaaS systems:
- Generic event names:
Updated,Changed,Modifieddo not give support, finance, or analytics teams enough meaning later. - UI-shaped events: frontend workflow details should not define domain history.
- Manual mutation of old events: once engineers start editing history directly, the audit trail stops being trustworthy.
- No replay drills: if nobody has rebuilt projections from scratch under realistic data volume, recovery is still theoretical.
Production event sourcing rewards disciplined naming, careful versioning, and projector design that assumes retries will happen. The payoff is substantial. You get a system that can explain billing history, support complex workflows, and feed analytics without reverse-engineering meaning from row diffs.
Unlocking SaaS Growth with Event Sourcing
The business value of event sourcing javascript isn’t that it feels architecturally pure. The value is that it turns software history into an operating asset.
That matters most in SaaS because the product is rarely just a UI over data. It’s a chain of business commitments. Pricing changes, customer lifecycle transitions, workflow automation, eligibility logic, and support actions all depend on knowing not only what is true now, but how it became true.

Audit trails stop billing and compliance pain
In a growing SaaS company, billing disputes are expensive because they consume engineering, support, and finance at the same time. A current-state row can tell you what a subscription looks like now. It usually can’t tell you the exact sequence of upgrades, proration steps, coupon applications, and cancellation timing that produced the invoice under dispute.
An event-sourced model can.
That’s why this approach works so well for subscriptions, CRM workflows, and approval-heavy systems. You gain a durable history that support can inspect, finance can verify, and engineering can replay when something looks wrong.
A clean audit trail also changes internal behavior. Teams stop arguing from screenshots and partial logs. They start reading the same source of truth.
Workflow automation becomes safer
Long-running workflows are where CRUD systems often become brittle. A lead enters a nurture sequence, sales overrides a stage, enrichment data arrives late, an AI scoring step reclassifies the account, and a downstream process still assumes the old state.
With event sourcing, each transition is explicit. That makes automation safer because each step reacts to named business facts instead of inferred row changes.
Examples where this helps:
- CRM qualification flows: events can represent lead captured, enriched, scored, assigned, contacted, and qualified.
- Client onboarding: teams can track invitation sent, documents received, review approved, kickoff scheduled.
- Subscription lifecycle automation: upgrade, proration, pause, resume, and cancellation can all feed downstream workflows reliably.
When companies want to staff these systems quickly, one practical route is to hire LATAM developers with strong Node.js and TypeScript experience. Event sourcing works best when the team can model domain behavior carefully, and hiring breadth helps when you need both backend design and operational discipline.
SaaS growth gets messy before it gets impressive. Systems that preserve the timeline handle that mess better.
Analytics get richer because history stays intact
CRUD systems are good at answering, “What is the value right now?” They’re weaker at answering, “How did customers move through the system over time?”
That difference is huge for product and revenue analytics.
With event sourcing plus projections, you can build views around behavioral history:
| Business question | Why event history helps |
|---|---|
| Which lifecycle transitions correlate with expansion? | You can analyze event sequences, not just final account state |
| Where do onboarding flows stall? | You can inspect the exact transition path and timing |
| Which support actions often precede churn? | You can correlate operational events with downstream outcomes |
| Why did this KPI shift? | You can rebuild projections after adjusting business logic |
Many founders finally see the strategic value. The same architecture that gives support better debugging also gives leadership better intelligence. You’re no longer limited to snapshots of current truth. You can analyze movement, sequence, delay, reversal, and recurrence.
Time-travel debugging is a business feature
Engineers often describe replay as a debugging advantage, which it is. But in SaaS, it’s also a customer trust feature.
If a client says, “Your automation changed our workflow last Tuesday,” you can inspect the actual state history around that moment. If an invoice looks wrong after a pricing rollout, you can replay the aggregate with corrected projector logic. If a read model was corrupted, you can rebuild it from the event log instead of patching rows manually.
That kind of recoverability is hard to price until you need it. Then it becomes one of the most valuable capabilities in the product.
Conclusion and Key JavaScript Libraries
Event sourcing javascript is not the right default for every app. If your product is a thin CRUD admin tool with modest workflow complexity, a relational model and careful auditing may be enough. But once your SaaS depends on historical truth, automation chains, billing correctness, or replayable analytics, current-state storage starts to fight the business.
The practical pattern is straightforward even if the implementation discipline is not. Model business facts as immutable events. Rebuild aggregates from ordered streams. Keep reads separate through projections. Add snapshots when hot streams grow. Treat schema evolution as a first-class concern early, not a cleanup task later.
The library choice matters less than the quality of your domain model, but tools still shape how quickly a team can move.
JavaScript Event Sourcing Libraries Comparison
| Library | Core Concept | Best For | Learning Curve |
|---|---|---|---|
| EventSourcing.NodeJS | Production-style examples for streams, ordered events, rehydration, and snapshots | Teams that want to learn the mechanics deeply and build a custom implementation | Medium |
| wolkenkit-cqrs | CQRS and event-driven application structure with stronger framework opinions | Teams that want more scaffolding around evented application design | Medium to high |
| event-sourcing-nestjs | Event sourcing patterns integrated into a NestJS application style | NestJS teams that want to stay inside familiar framework conventions | Medium |
| Custom PostgreSQL approach | Append-only event tables, explicit aggregates, projector workers, and tailored read models | SaaS teams that need control, auditability, and gradual adoption in an existing Node.js stack | Medium to high |
How to choose without wasting months
A few decision rules help:
- Choose examples-first tooling if your team still needs to internalize the model. A lightweight approach exposes the mechanics clearly.
- Choose a framework-heavy option if your team already agrees on the domain and wants consistency more than flexibility.
- Choose a custom PostgreSQL design when auditability, operational control, and incremental migration matter more than framework speed.
- Avoid overcommitting too early to a platform whose abstractions hide stream ordering, versioning, and projection behavior.
The best first production candidate is usually not your entire system. It’s one area where history matters enough to justify the pattern. Billing is a strong candidate. So is subscription lifecycle management. CRM workflow orchestration is another.
Start where the business already asks historical questions that your current database cannot answer well.
If the product’s real logic lives in the sequence of changes, store the sequence of changes.
Once a team sees that replay can explain customer state, rebuild views, and support automation with confidence, event sourcing stops looking exotic. It starts looking like the missing layer the product needed all along.
If your team wants help designing auditable workflows, event-driven SaaS backends, or AI-powered operations on top of a clean historical data model, MakeAutomation can help you implement the architecture and automation stack without turning it into an academic science project.






