

What Is a Transitive Dependency: Understanding Its Impact
A release candidate is ready. Sales has already promised the feature to customers. Then the build breaks because two libraries deep in the dependency tree want incompatible versions of the same package.
Or the product ships, but a CRM record starts showing the wrong regional office details after one routine update. Nobody touched that field directly. Yet the data is now inconsistent across reports, workflows, and downstream automations.
Leaders usually see these as separate problems. One belongs to engineering. The other belongs to data quality. In practice, they often share the same pattern: a hidden indirect relationship that nobody was actively managing.
That pattern is called a transitive dependency.
If you're asking what is a transitive dependency, the short answer is this: something your system relies on indirectly, through something else it already depends on. That sounds abstract until it blocks a deployment, corrupts a dashboard, or opens a security hole in software your team didn't even know was running.
The Silent Threat to Scalability and Security
A lot of scaling problems don't begin with a dramatic outage. They begin with confusion.
A team adds one library to speed up feature development. Another team updates a customer data model to support a new workflow. Weeks later, engineers are chasing a build conflict, while operations staff are reconciling records that no longer match between systems.
Nobody intended to create fragility. They inherited it.
Two symptoms, one pattern
In software, the failure often appears as a mysterious dependency conflict, an unexpected vulnerability alert, or a bloated deployment pipeline. Teams may think they only added one package, but that single choice can pull in a much larger chain of indirect components. If you're tightening release discipline around an Auto DevOps pipeline, these hidden relationships are often what turns a clean workflow into a fragile one.
In data systems, the symptom looks different. A customer attribute lives in one table because it felt convenient at the time. Later, that attribute really depends on another non-key field instead of the actual business entity it belongs to. Updates become inconsistent. Deletions remove information you still needed. Insertions require awkward workarounds.
Hidden dependencies don't stay hidden when a business grows. They surface as delays, rework, and trust problems.
Why leadership should care
This isn't just a technical housekeeping issue. It affects three things leaders watch closely:
- Release velocity because indirect software dependencies can break builds and slow change approval.
- Data trust because indirect database relationships can create conflicting records across CRM, reporting, and automation systems.
- Security exposure because teams often monitor what they chose directly, not what arrived indirectly.
When those risks start stacking up, outside review helps. Deep systems issues often need someone who can connect architecture, operational risk, and remediation strategy, which is why teams sometimes bring in expert security consultation when hidden dependency chains are affecting both delivery and compliance.
Understanding the Core Concept of Transitive Dependency
The easiest way to understand a transitive dependency is with a simple analogy.
You trust Friend A. Friend A relies on Friend B. Friend B relies on Friend C. Even if you've never met Friend C, your outcome still depends on them.
That is the core idea.
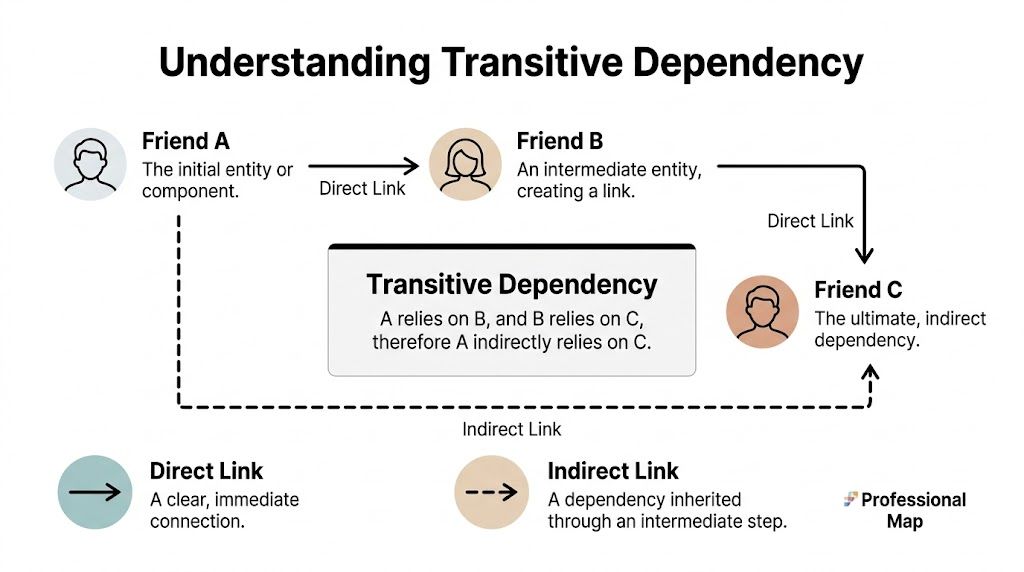
The plain-language definition
A transitive dependency exists when one component depends on another component indirectly through an intermediate component.
There are two places leaders run into this most often:
- Database design
- Software package management
They use the same word, but the operational problem looks different in each case.
In databases
In a relational database, a transitive dependency happens when a non-key attribute depends on another non-key attribute, which depends on the primary key. This violates Third Normal Form, or 3NF, a normalization rule introduced by Edgar F. Codd in his 1970 work on relational data models. A concise summary appears in the Wikipedia overview of transitive dependency.
A practical example looks like this:
- Book determines Author
- Author determines Author_Nationality
- therefore Book indirectly determines Author_Nationality
That indirect chain is the problem. The nationality doesn't really belong to the book. It belongs to the author.
The result is operational friction. The same reference data gets repeated across rows. Teams update one row and forget another. Reports stop agreeing with each other.
If your teams are standardizing schema quality, a useful companion concept is database normalization forms, because transitive dependency only makes full sense when you see how table structure controls data integrity.
In software
In software, the same logic applies to packages and libraries.
Your application depends directly on Package A. Package A depends on Package B. Package B depends on Package C. Even though your team never selected C, your application still depends on it.
This matters a lot in modern integrations. A single framework, plugin, or SDK can bring a large chain of indirect code into your environment. That becomes especially important in platform work, API-heavy products, and any initiative involving legacy modernization or integrating software systems, where hidden dependencies can cut across vendors, teams, and deployment boundaries.
Practical rule: If your system only works because something indirect works, that indirect component is part of your risk surface.
Real-World Examples in Databases and Software
Abstract definitions are useful, but transitive dependencies are often recognized only when seen in a business workflow.
A database example from a CRM
Suppose your CRM has one table like this:
| Lead_ID | Lead_City | Regional_Office_Address |
|---|---|---|
| L-101 | Austin | Office A |
| L-102 | Austin | Office A |
| L-103 | Denver | Office B |
At first glance, this seems practical. Everything is in one place.
But look at the dependency chain:
- Lead_ID identifies Lead_City
- Lead_City determines Regional_Office_Address
- therefore Lead_ID indirectly determines Regional_Office_Address
That is a transitive dependency.
Now imagine the Austin office moves. Your team has to update every Austin lead row. If one row is missed, reports and automations now disagree. Routing rules may send leads to one address while dashboards show another.
A more stable design separates the city-to-office relationship into its own table. That's the same logic behind third normal form with example, where data gets split according to what depends on what.
A software example from a modern app stack
Now switch contexts.
A frontend team installs a package for one visible feature. The line added to the project manifest looks small. The hidden tree behind it may not be small at all.

A verified summary from OX Security reports that a 2023 Sonatype report found average Java projects with 50-100 direct dependencies often pull in 1,000-5,000 transitive dependencies, increasing vulnerability exposure by 400%, and that 85% of supply chain attacks in 2024 for JavaScript apps exploited unmonitored transitive paths, as described in OX Security's review of the risks of transitive dependencies in software development.
That explains why teams get surprised.
They believe they approved a known library. In reality, they approved a graph of indirect code with its own version constraints, licenses, and security posture.
What leaders should notice
The pattern is the same in both worlds:
- The direct item looks harmless
- The indirect chain creates the primary risk
- The cost appears later, during change
In databases, the penalty shows up as anomalies and rework. In software, it shows up as conflict, bloat, and attack surface. The technical mechanisms differ, but the management mistake is identical. Teams govern what they can see directly and neglect what arrived through inheritance.
The Hidden Risks and Business Impacts
The damage from transitive dependencies isn't theoretical. It lands in budgets, delivery plans, and customer trust.
Data integrity breaks quietly
In databases, transitive dependencies produce anomalies.
An update anomaly happens when the same fact is duplicated in many rows and your team changes only some of them. An insertion anomaly happens when the design forces staff to enter unrelated data together. A deletion anomaly happens when removing one record accidentally removes information the business still needs.
These failures are dangerous because they often look like ordinary human error. The root issue is structural. The schema allowed one business fact to depend on another non-key attribute instead of the right entity.
Build reliability gets worse as systems grow
In software, transitive dependencies increase fragility in places leaders notice fast.
A release pipeline slows down because dependency resolution takes longer. A build fails because two direct libraries want conflicting versions of an indirect package. A container becomes larger than expected because unnecessary packages came along for the ride. None of this creates customer value, yet engineers spend time resolving it.
If a team can't explain why a package is in production, they also can't explain its operational cost.
Security risk concentrates in the indirect layer
This is the most urgent issue.
Research from Endor Labs found that 95% of vulnerabilities found in modern applications exist within transitive dependencies rather than direct dependencies, which means a scanning approach focused only on directly chosen packages misses most of the actual risk surface. Endor Labs explains this concentration in its write-up on transitive dependency vulnerabilities and SCA.
That changes how leaders should think about software risk. The biggest exposure often isn't in the library your developers intentionally selected. It's in the deeper chain they never reviewed in detail.
Why this matters operationally
For a B2B or SaaS company, that affects more than security.
- Customer trust drops when incidents trace back to components the company didn't know it depended on.
- Compliance conversations become harder when teams can't account for the full software bill of materials.
- Incident response slows down when nobody knows which applications inherited the vulnerable component.
Log4Shell became such a large remediation problem for exactly this reason. The vulnerable code often arrived through indirect dependency chains, not as a clearly visible top-level choice.
How to Identify Transitive Dependencies in Your Systems
You can't manage what you can't see. Separate discovery methods are typically required for databases and software.

How to spot them in a database
Start with one table that feels overloaded. CRM tables, order tables, and operational reporting tables are common candidates.
Ask these questions:
- What is the primary key? Write down the one field that uniquely identifies each row.
- Which attributes depend directly on that key? These usually belong in the table.
- Which attributes depend on another non-key field? Those are your likely transitive dependencies.
A quick review often reveals the pattern. If Regional_Office_Address depends on Lead_City instead of Lead_ID, the address probably belongs in a separate reference table.
A useful practical test is this: if one real-world fact can change independently of the row's main entity, it may not belong in that table.
How to spot them in software
Package managers already provide basic visibility.
Common commands include:
- npm projects using
npm ls --all - Maven projects using
mvn dependency:tree
These commands don't solve the problem, but they expose the tree. That alone changes conversations. Teams move from "we use a few packages" to "we inherited a graph."
A visual explanation can help when you're training non-specialists or reviewing system debt with mixed teams.
Where automated tooling becomes necessary
Manual review stops working once projects become large.
At that point, teams need Software Composition Analysis, or SCA, to map direct and transitive dependencies, flag vulnerable components, and show why a given package is present. Good tooling also helps identify deep dependency paths that don't appear in the main manifest file.
Operational shortcut: Don't ask only "What did we install?" Ask "What arrived because we installed it?"
For leadership teams, the key deliverable isn't the raw graph. It's visibility that supports decisions. Which inherited components are critical, which are stale, and which have risk without business value.
Strategic Resolution and Long-Term Management
Finding transitive dependencies is only the start. Resolution requires a different playbook for databases and software, but the governing principle is the same: reduce hidden inheritance and automate oversight.

For databases, normalize the schema
When a non-key attribute depends on another non-key attribute, split the design so each fact lives with the entity it describes.
Take the earlier CRM pattern:
Before
- Lead table contains
Lead_ID,Lead_City, andRegional_Office_Address
After
- Lead table contains
Lead_IDandLead_City - Office table contains
Lead_CityandRegional_Office_Address
The address now belongs to the city-to-office relationship instead of being copied onto every lead. That reduces duplication and makes updates consistent.
For software, govern the dependency graph
Software remediation is less about one cleanup and more about operational control.
Some practical actions:
- Pin versions with lock files such as
package-lock.jsonso environments stay predictable. - Audit regularly so obsolete or vulnerable indirect packages don't linger.
- Prune unused packages because every unnecessary dependency expands the graph.
- Review conflicts early before they surface during release windows.
Build an ongoing control system
Modern applications often include thousands of transitive dependencies, so automated tooling is mandatory. Black Duck describes a six-step methodology: generate SBOMs, validate them, analyze for vulnerabilities, remediate, monitor changes, and share information, and notes that this investment improves operational reliability for SaaS platforms in its guidance on managing transitive dependencies.
That six-step model works well because it turns dependency management into a repeatable operating process.
| Area | Short-term fix | Long-term control |
|---|---|---|
| Database | Decompose tables | Schema review standards |
| Software | Pin and update packages | Automated SCA and SBOM workflows |
The main management lesson is simple. If dependency control depends on memory, it will fail. If it runs inside build, review, and release workflows, it becomes durable.
Best Practices for Automated B2B and SaaS Stacks
Leadership teams need a governance model, not a scattered set of fixes.
A strong approach treats transitive dependencies in software and databases as one class of business risk: indirect dependencies that can affect delivery, integrity, and exposure without visible ownership.
Put inventory first
Enterprise applications consist of 80-90% third-party code, with 95% of vulnerabilities hiding in transitive dependencies, and Kusari notes that B2B SaaS leaders can reduce this risk by using automated SCA tools with reachability analysis in its overview of what a transitive dependency is.
That makes inventory the starting point.
For software, maintain a current SBOM for each critical service. For databases, keep a documented map of core entities and reference tables so teams can see where business facts belong.
Move from awareness to policy
The strongest teams don't rely on individuals remembering good practice. They encode it.
Consider a governance model like this:
- Block risky additions automatically when CI detects unacceptable dependency conditions.
- Review inherited software, not just chosen software during architecture decisions.
- Treat schema review as part of delivery when CRM, billing, or workflow data models change.
- Prioritize by reachability so teams focus first on vulnerable code paths that can execute.
Give leaders the right questions
You don't need to read build graphs or database theory to manage this well. You do need sharper questions.
Ask your teams:
- Can we list our critical indirect software dependencies?
- Which database tables still contain facts that belong in separate reference entities?
- Which inherited components are high risk but low value?
- Where do release or data-quality incidents trace back to hidden dependency chains?
The companies that scale cleanly don't eliminate complexity. They make inherited complexity visible and govern it continuously.
Frequently Asked Questions About Transitive Dependencies
Is a transitive dependency always bad
No. It's often unavoidable.
The problem isn't that indirect dependencies exist. The problem is letting them remain invisible, unreviewed, or structurally misplaced.
Are database and software transitive dependencies the same thing
They share the same logic of indirect reliance, but they appear in different forms.
In databases, the issue is a dependency relationship between data attributes. In software, it's an indirect package or library pulled into your application through another package.
Why do teams miss them so often
Because people usually review what they added directly.
A developer sees the top-level package. An operations manager sees the visible table fields. The inherited chain underneath often isn't obvious without tooling or schema review.
What should a leadership team do first
Start with visibility.
Ask engineering for a dependency tree and an SBOM for critical applications. Ask data owners to identify tables where one business fact appears to depend on another non-key field. Those two moves usually reveal the biggest hidden risks quickly.
MakeAutomation helps B2B and SaaS teams turn hidden system complexity into controlled, scalable operations. If you need support improving dependency visibility, hardening automation workflows, cleaning up CRM data structures, or operationalizing AI and process automation, explore MakeAutomation.






